2025年02月10日
写下这篇构建个人专属知识库的避坑教程,那是因为过去一直趴在坑里。
自从ChatGPT 4发布后,曾想借助AI大模型构建起自己专属的知识库。历经一年多的测试和使用,散落在各处的知识库估计已布满灰尘,究其原因仍然是大模型不够聪明!要么内容训练深度不够导致查询触发率低;要么大模型推理分析能力差,不能领会自己专属物料的思想精华以致一本正经在胡说八道。现在DeepSeek R1横空出世,让个人构建可用的本地知识库迈出实际性的第一步,当然未来随着大模型的迭代升级,必将更实用。
本人喜欢极简,以下一张图概括踩坑和避坑指引:
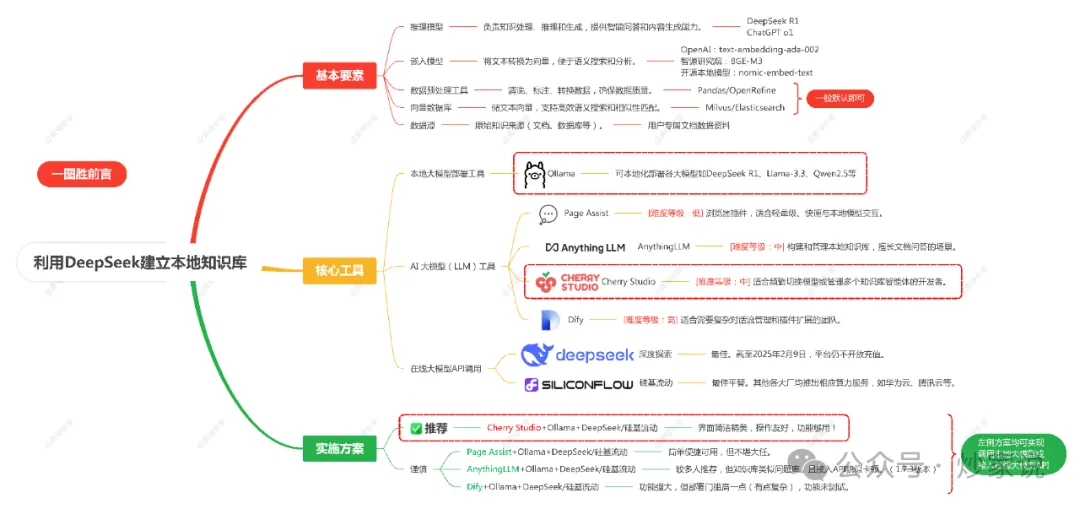
作为普通人、性能较好的办公电脑构建本地知识库的方案是:

以下为教程步骤:
一.安装部署本地大模型工具:Ollama
1.点击下载安装:ollama https://ollama.com

按默认安装操作即可。安装完,每次启动大模型则在任务栏上有显示,不需进行其他设置。(以macOS为例,Windows在下方任务栏)

2.下载DeepSeek R1大模型。
(1)点击进入DeepSeek R1下载页面https://ollama.com/library/deepseek-r1

(2)选择合适版本的大模型。建议安装7B版本。
不同规模的模型,建议电脑配置的要求如下:
1.5B 模型:最低要求内存8GB以上,CPU、GPU差一点均可。
7B 模型:内存16GB以上,且GPU至少8GB、CPU 8核以上。(普通办公电脑极限安装版本,性能好运行大模型则快)
**8B 、14B、32B模型:**非发烧玩家不可,选择此版本以上的都无需看我教程了。
(3)通过终端或命令行窗口粘贴对应版本的命令即可。如下载1.5B版本命令如:ollama run deepseek-r1:1.5b,粘贴至终端回车即可。

(4)下载安装文本向量化本地模型:BGE-M3或nomic-embed-text(选其一即可)。
通过终端或命令行窗口粘贴相应命令:
BGE-M3:ollama pull bge-m3
nomic-embed-text:ollama pull nomic-embed-text
3.到此Ollama本地大模型运行工具和模型文件均部署完毕。
如果选择接入线上的大模型API,则以上步骤均可略过!
二.安装大模型应用**工具:**Cherry Studio
1.点击下载安装Cherry Studio https://cherry-ai.com/download

2.配置本地大模型
(1)按照以下图示步骤设置添加本地相关模型。

(2)建立本地知识库(按图示步骤)

(3)配置对话模型并开启知识库互动问答

(4)使用效果

**备注:**本地电脑配置不高,无法使用DeepSeek R1满血版,本地大模型信息处理结果和效率是值得商榷的!
三.配置调用在线满血版DeepSeek大模型
本地电脑配置的限制,建议普通玩家还是充值调用满血版的大模型。当然你对知识库保密性有极高要求,那就购置高性能设备即可。
由于DeepSeek官网仍未开发API充值,故选择硅基流动替代使用。
1.点击注册 硅基流动账号 https://cloud.siliconflow.cn/i/EvC62OVg

2.登录账户。可进行实名验证、新建API、充值等。如下所示。

3.配置大模型API
(1)填写在硅基流动上申请的API。
(2)填写API地址:https://api.siliconflow.cn
(3)选择添加相关大模型:deepseek-ai/DeepSeek-R1、Pro/deepseek-ai/DeepSeek-R1、BAAI/bge-m3等。
(4)详情如图示:

